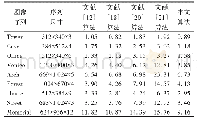
《表1 MCNN模型结构:基于多分辨率时频特征融合的声学场景分类》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
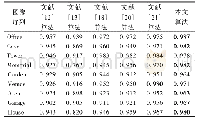
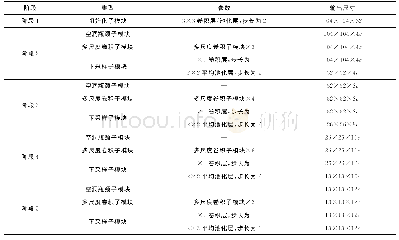
为此,我们在CNN中采用不同尺寸的卷积核和池化窗组合,力求同时捕捉细节和宏观信息。由于第二层卷积输出的高级特征来自于不同的子模型,每个子模型输出特征由同一输入特征图上不同大小的感受野提取得到,所以称之为多分辨率卷积神经网络(MCNN),模型结构和参数如表1所示。其中,在输入层分别采用了5×5卷积+1×5池化、7×7卷积+1×10池化、3×3卷积+1×2池化操作,在中间层分别采用了5×5卷积+1×100池化、7×7卷积+1×50池化、3×3卷积+1×250池化。这些参数都是经过组合实验优选出来的结果。
| 图表编号 | XD00155087000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 姚琨、杨吉斌、张雄伟、郑昌艳、孙蒙 |
| 绘制单位 | 陆军工程大学、陆军工程大学、陆军工程大学、陆军工程大学、陆军工程大学 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}