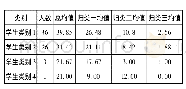
《表9 分类结果的基本统计量》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《大一新生数学基本活动经验状况及其对大学数学学习的影响》
确定聚类分析中类的个数有几种常见方法,如根据适当的阈值或根据点的散布图直观确定等。此研究中我们根据表8中的统计量(半偏R方统计量、伪F统计量、伪t方统计量),近似检验合适的类个数。伪F统计量的值越大,表示这些观测样本可显著地分为几类。表8中伪F统计量最大时的聚类数是4,说明根据伪F准则,分为4个类是较为合适的;R方统计量用于评价每次合并成N个类时的聚类效果,R方越大说明N个类越分开,聚类效果好。R方的值随着分类个数N的减少而减少。由表8可知,分为4个类前,R方的减少是逐渐的,而下一次合并后分为两类时,R方下降较多。通过分析R方统计量,可得出分为4个类是较合适的。可见,R方准则和伪F统计量准则均支持分为四类。据此,研究将测试学生群体分为四类,分别对应学生类别一、学生类别二、学生类别三和学生类别四。四类学生的基本信息如表9。
| 图表编号 | XD00153862200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.20 |
| 作者 | 郭玉峰、郑悦、于化隆、齐景繁 |
| 绘制单位 | 北京师范大学数学科学学院、北京师范大学数学科学学院、北京师范大学统计学院、北京师范大学数学科学学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}