《表4 现有无监督的方法在DukeMTMC-reID数据集上的结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对于基于伪标记的方法,TJ-AIDL[46]是通过结合属性学习并对目标域中的数据生成伪属性的方法来进行学习的;TFusion-uns[47]利用时序信息产生更可靠的伪标记信息;PAUL[44]和MAR[43]以有标记的源域数据为基准,生成无标记目标域的伪标记信息;DC[55],HCR[99],BUC[52],PCB-R-PAST[50],SSG[48],ISSDA[53]和ACT[54]都是基于聚类的算法,其中,ACT对聚类后的结果进行了进一步处理,以便于找出确定性的伪标记信息和非确定性的伪标记信息,因此相对于其他方法,该方法能够得到相对更好的结果.另外,从表3和表4中可以发现,基于聚类的伪标记方法相对于其他伪标记的方法有更好的性能.
| 图表编号 | XD00153551900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 祁磊、于沛泽、高阳 |
| 绘制单位 | 计算机软件新技术国家重点实验室(南京大学)、计算机软件新技术国家重点实验室(南京大学)、计算机软件新技术国家重点实验室(南京大学) |
| 更多格式 | 高清、无水印(增值服务) |

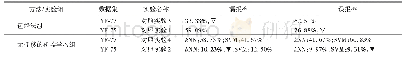




{kind=link}