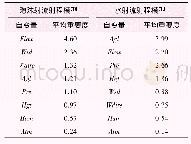
《表1 人口随机森林模型变量重要性排序》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于卫星遥感的长江三角洲地表热环境人口暴露空间特征》
注:NIL(Night Time Light)为夜间灯光,NDVI为归一化植被指数,DEM为数字高程模型。
随机森林是一种灵活的、便于使用的机器学习算法,即使没有超参数调整,大多数情况下也会带来好的结果,它可以用来进行分类和回归任务[21 24]。根据已有研究的基于NPP/VIIRS的空间化人口方法[20,29],本研究参考叶婷婷等人的随机森林模型[19],采用了NTL(Night Time Light),NDVI,DEM和坡度4个自变量,构建人口随机森林空间分布模型。将2016年长江三角洲1km×1km的4个栅格图层(NTL,NDVI,DEM和坡度)按区县进行分区统计,然后计算区县普查人口密度的对数,将各区县人口密度对数作为因变量,各区县平均NLT、NDVI、DEM,和坡度作为自变量,输入人口随机森林模型进行预测,随后计算每个网格区域的分布权重,最后对预测结果进行分布权重调整,获得2016年长江三角洲1km×1km格点的人口空间分布估算结果。考虑运算性能和模型精度,设定随机森林模型中生长的树的数目(ntree)为500,在每一个分裂节点处样本预测器个数(mtry)为2。通过建模,最终给出了变量重要性排序(表1)。
| 图表编号 | XD00153373100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 李佳雯、杨彬云、张曼玉、王泓、杨元建、高志球 |
| 绘制单位 | 南京信息工程大学地理科学学院、河北省气象科学研究所、南京信息工程大学大气物理学院、南京信息工程大学大气物理学院、南京信息工程大学大气物理学院、香港中文大学环境能源及可持续发展研究所、南京信息工程大学大气物理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}