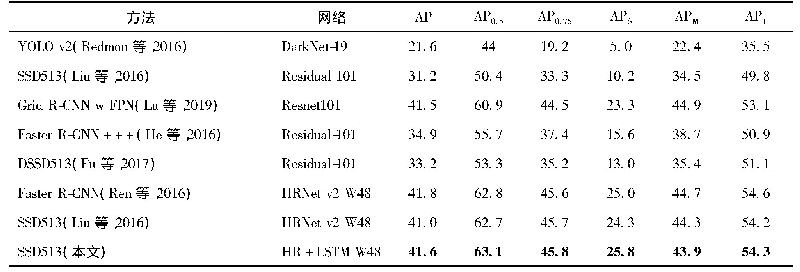
《表1 Baseline,Luong等的方法,Zhang等的方法以及本文方法在Dutch Census数据集上的歧视性样本消除效果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《公平性机器学习中基于分类间隔的歧视样本发现和消除算法》
表1展示了3种方法以及不考虑歧视情况下的Baseline在数据集Dutch Census上的歧视性样本消除效果.实验结果如图4所示,横坐标代表分类准确性和公平性准则demographic parity,equalized odds,纵坐标代表这3个指标的具体数值.图4和表1中的结果均表明通过数据预处理获得公平的学习模型在分类公平性增加的同时会造成不同程度预测准确性的降低.但不同的是,与Baseline相比Zhang等[4]和本文的方法能够获得很好的分类公平性,而Luong等[3]提出的方法的分类公平性效果提升不明显.Luong等[3]提出的方法由于没有考虑到不同属性对于发现歧视样本的重要性不同,因此处理后的数据集中仍然有很大的歧视,并且随机选取一部分样本进行歧视发现和消除,模型准确度损失过大.Zhang等[4]和本文的方法都能够实现分类公平.但是如图4和表1所示,Zhang等[4]只使用了对标签预测有重要影响的属性,并进行二值化处理,尽管能够确保公平性但预测准确度的损失较大本文使用基于最大间隔原理来寻找近邻样本,使得歧视样本的选取更合理,并且为了保证分类公平性的同时尽可能降低模型精度的损失,基于最大间隔原理将样本进行投影后选取目标集,只在目标集中选取歧视样本并进行修正.总体而言,与Luong等[3],Zhang等[4]和Baseline比较,本文的方法在不损害太多预测准确性的情况下获得很好的分类公平性.
| 图表编号 | XD00153141800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.20 |
| 作者 | 石鑫盛、李云 |
| 绘制单位 | 南京邮电大学计算机学院、南京邮电大学江苏省大数据安全与智能处理重点实验室、南京邮电大学计算机学院、南京邮电大学江苏省大数据安全与智能处理重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}