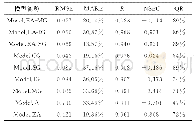
《表6 几种模型预测结果评价对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
所建立模型计算的结果有2种:离散值1和0表示的滑坡与非滑坡,以及区间为[0,1]的连续值的概率属性值P。利用结果进行分析并对斜坡单元赋概率属性值P,概率为1表示肯定发生滑坡;概率为0表示肯定不发生滑坡;概率越接近1表示滑坡发生的可能性越大。模型预测精度结果如表2~6。从表中可以看出总体正确率中,就研究单元而论,栅格单元的总体精度要比对象单元的高,但从使用者精度和生产者精度角度分析,对象单元的精度比栅格单元的要高,出现这种现象的原因就是栅格单元的样本总数63 079远大于对象单元的样本总数569,且非滑坡单元数远大于滑坡单元。就预测模型而言,支持向量机(SVM)的正确率要比决策树的高。针对上述情况,为了使不同模型和单元之间更具可比性,引入Kappa系数。Kappa系数也是一种精度评价指标,它是一种内部一致性系数,取值在0~1之间。当2个变量均为有序分类的情况下使用一致性系数指标,它是在综合使用者精度和生产者精度2个参数基础上提出的一个总结性指标,用来评价分类预测图像的精度问题,其值越大则表示预测精度越好,反之则越差。从表6可以看出,针对同一模型,对象单元的Kappa系数优于栅格单元。针对同一数据单元,SVM模型的Kappa系数优于决策树模型。
| 图表编号 | XD00150731100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.28 |
| 作者 | 艾力、杨冰玉、郭丽 |
| 绘制单位 | 中陕核工业集团地质调查院有限公司、中陕核工业集团地质调查院有限公司、中陕核工业集团地质调查院有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}