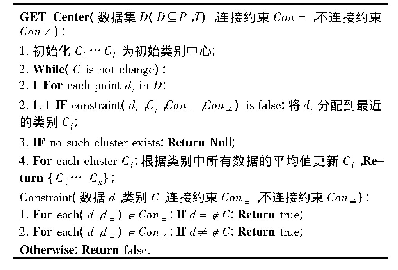
《表3 K-means++服务聚类算法(算法2)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文采用K-means++聚类算法来对车联网业务进行分类,其伪代码如表3所示。其分为4个步骤,分别是选择聚类中心、聚类、重新计算聚类中心、迭代。为了保证输入数据集的顺序不会对结果产生影响,在初始聚类中心的选择中应尽可能的使聚类中心间的距离较远。同时需要特别注意的是,在步骤2中需要考虑服务需求指标的影响因子对聚类的条件的影响,即对样本到聚类中心的距离的计算的影响。
| 图表编号 | XD00146214700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 吴大鹏、郑豪、崔亚平 |
| 绘制单位 | 重庆邮电大学通信与信息工程学院、重庆高校市级光通信与网络重点实验室、泛在感知与互联重庆市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}