《表3 带约束的K-means聚类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
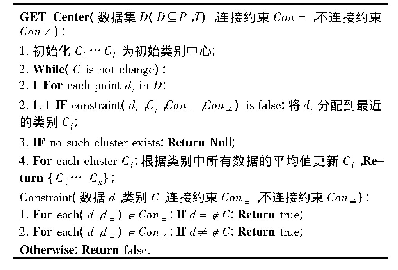
为了确定性能数据的类别,本文通过一组正负关联约束结合K-means的聚类原则对性能数据进行半监督聚类.首先将性能数据初始化为D,定义一对正关联约束(Con=)和负关联约束(Con≠),根据K-means的聚类原则,首先随机初始化类别中心C,针对D中的性能数据di在满足约束关系的前提下将其就近分配到Cj.以di到Cj的平均距离对Cj进行更新,并对D中的性能数据di在不违反约束关系的前提下就近分配类别,直到Cj不再发生变化,通过评估聚类效果来确定最佳k值.带约束的K-means聚类算法如表3所示.
| 图表编号 | XD00213662500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.01 |
| 作者 | 张晓江、姜瑛 |
| 绘制单位 | 昆明理工大学云南计算机技术应用重点实验室、昆明理工大学信息工程与自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}