《表1 Kinetics数据集上动作识别精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
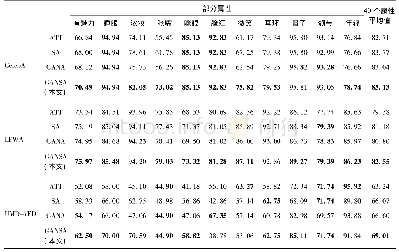
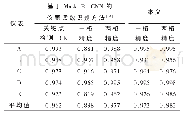
表2给出了UCF101在Kinetics数据集上预训练后的模型上的动作识别精度,在预训练模型上UCF的训练时间大幅减小,得到的结论也与上述一致,R(2+1)D模型的表现最好。根据Varol等[19]的研究发现,使用长期卷积(LTC)在较长的输入剪辑(例如,100帧)上训练视频CNN,可以获得准确度增益。笔者也对输入剪辑的帧数进行了比较,如图12和图13所示,大部分模型在将8帧为一个剪辑设置成16帧为一个剪辑后,识别精度均有提升。针对此问题做了2个实验,在第1个实验中,采用8帧的剪辑训练的模型,并使用32帧的剪辑作为输入进行测试。结果发现,与8帧剪辑相比,识别精度下降5.8%。在第2个实验中,使用在8帧的剪辑预训练后的模型参数微调32帧模型。在这种情况下,网络实现的结果几乎与在32帧剪辑中从头学习(68.0%对比69.4%)时的结果相同。然而,从8帧预训练参数中微调32帧模型大大缩短了总训练时间。上述2个实验表明,对较长剪辑进行训练会产生不同(更好)的模型,因为模型会学习更长的时间信息。表3给出了Kinetics数据集上在不同长度的剪辑上训练和评估的18层R(2+1)D的总训练时间和准确度。
| 图表编号 | XD00146079900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 赵维、沈柏杉、张宇、孔俊 |
| 绘制单位 | 吉林警察学院信息工程系、东北师范大学信息科学与技术学院、东北师范大学信息科学与技术学院、东北师范大学信息科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}