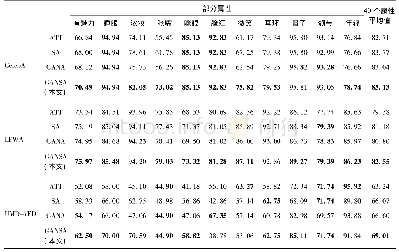
《表4 不同方法在MMI数据集上的识别准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:加粗字体为最优值。
MMI数据集识别准确率如表4所示,基于运动单元的深度网络(AU-aware deep networks,AUDN)结合AU信息,设计了一个AU感知机提取AU相关特征用于表情识别(Liu等,2013)。表情分解获得残差的方法(de-expression residue learning,DeRL)认为表情由身份信息和纯表情因子组成,提出用生成对抗网络(generative adversarial network,GAN)生成不同表情的样本,中间层包含表情因子,融合多个中间特征用于分类(Yang等,2018)。基于深度学习的人脸表情识别方法CNN(Inception)设计了一个较深的网络,包含多个inception结构用于识别人脸表情(Mollahosseini等,2016)。与上述两个数据集一致,为表明方法的有效性,增加了上述对比实验,表4中的实验结果表明了本文方法在MMI数据集上的有效性。本文所对比经典方法的准确率均是原文献中给出的结果,本文在进行实验时,保证实验设置与对比方法保持一致。
| 图表编号 | XD00141912000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.16 |
| 作者 | 王善敏、帅惠、刘青山 |
| 绘制单位 | 南京信息工程大学自动化学院江苏省大数据分析技术重点实验室、南京信息工程大学自动化学院江苏省大数据分析技术重点实验室、南京信息工程大学自动化学院江苏省大数据分析技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}