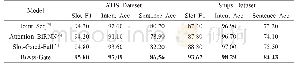
《表4 与其他模型实验的对比结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《融合BSRU和ATT-CNN的化学物质与疾病的关系抽取方法》
表4中第一种方法使用基于规则的传统方法进行关系抽取,达到了60.8%的F1值.这种方法拥有一定的竞争力,但是由于规则依靠人工制定,导致此方法过于消耗时间和人力资源.第二种方法使用最大熵模型分别构建句内分类器和句间分类器,提出一种基于层次化的特征提取方法,是机器学习应用在关系抽取的较好尝试,模型在准确率方面表现优秀,在召回率方面表现相对较差.第三种方法使用上下文依存表示的卷积神经网络加上最大熵模型构建的关系分类器,可以更加准确的捕获实体关系的语义特征,最终达到了60.2%的F1值,与之前的机器学习方法相比有了更好的效果.第四种方法提出将LSTM与SVM结合的复合抽取模型,先分别使用LSTM和SVM抽取关系,再将它们的抽取结果进行线性融合,模型的召回率有了可观的提升,F1达到了63.7%,体现出循环神经网络对关系抽取的有效性.第五种方法使用SVM分类器加上多种统计特征、语言学特征和CTD知识库特征,扩充了训练实例和特征集,由于获取到的特征更多,使抽取的准确率有了较大的提升,F1值取得了67.1%的优秀表现.本文模型使用BSRU学习文本多种特征,ATT-CNN在减少噪声影响后使用不同大小的卷积核学习文本的多种特征,分段池化后通过分类完成关系抽取,与其他几种方法相比,模型可以获得更多的文本特征,降低噪声对抽取目标关系的影响,减少信息丢失,使准确率和召回率均有相应提高,验证了本文模型在生物医学文献中实体关系抽取的较好效果.
| 图表编号 | XD00141268300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 曹春萍、何亚喆 |
| 绘制单位 | 上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}