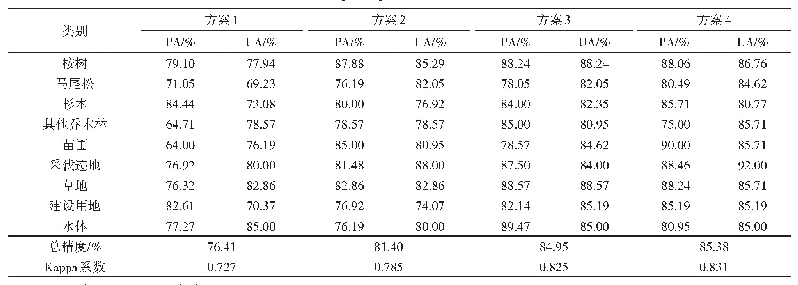
《表9 多分类结果比较(%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在数据不平衡的多分类问题中,由于少数类攻击的样本数较少,模型对其学习的不够充分使得在异常检测中倾向于选择数据集中的多数类,导致少数类的检测率不高进而造成较高的误报率,采取SMOTE-ENN过采样算法来处理数据不平衡问题.本文选择与单模型CNN、LSTM,混合模型CNN-LSTM、CNN-BLSTM等深度学习模型进行对比,检测指标包括各类别的检测率(DR),模型整体的准确率(Acc)与误报率(FAR).对比结果如表9所示,从表中可看出在模型的整体的准确率上,本文模型的实验结果优于其他深度学习模型,说明本文模型充分挖掘了网络流量中的空间特征与时序特征,并对其进行了有效的学习与训练,进而提升了模型整体的准确率.在误报率上,本文模型也取得了不错的效果,20.25%为所有模型中最低.对于少数类样本U2R与R2L,本文模型相比其他深度学习模型优势明显.本文模型在检测率,准确率以及误报率上均优于其他几种深度学习方法,说明本文模型不仅可以处理少数类样本检测率较低的问题而且对于测试集中存在的未知攻击样本也具有一定的检测能力.
| 图表编号 | XD00141266400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 郭文忠 |
| 绘制单位 | 福州大学数学与计算机科学学院、福建省网络计算与智能信息处理重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}