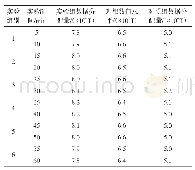
《表3 人员拟合与属性分类可靠性的对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《混合模型在英语听力诊断测评中的应用——基于Mixed-CDMs与G-DINA模型的对比分析》
据研究,lz指标(-2,2)被认为是最有力的人员拟合指标[37]。当lz<-2.0,表示该被试不拟合;当lz>2.0,表示该被试过度拟合;lz值越接近“0”,表示人员拟合性越好,而lz的绝对值(|lz|)表示人员偏离“0”的情况。人员拟合与属性分类可靠性[38]的对比如表3所示,可以看出:Mixed-CDMs与G-DINA模型中人员拟合绝对值的平均值相同,但有3名被试的拟合程度发生明显变化:在G-DINA模型中,被试ID 417为过度拟合,ID 537、ID 572均为不拟合,而这3名被试在Mixed-CDMs中都变成了拟合被试。此外,这3名被试的属性掌握模式也随之发生了改变:ID 417在G-DINA模型中的属性掌握模式为“0001000”,表示掌握了属性A4,而在Mixed-CDMs中调整为“0000000”,表示属性全未掌握;ID 537在G-DINA模型中掌握了属性A5和A7(属性掌握模式为“0000101”),而在Mixed-CDMs中仅掌握了A5(属性掌握模式为“0000100”)。由此可见,混合模型对属性掌握模式的估计更加严苛。
| 图表编号 | XD00140735800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 董艳云、马晓梅、孟亚茹 |
| 绘制单位 | 西安交通大学外国语学院、西安交通大学外国语学院、西安交通大学外国语学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}