《表3 基于字符级和词级CNN模型分类结果评估》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
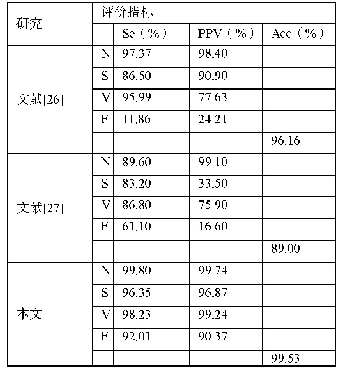
从表3实验结果来看,不管是采用自训练的词向量语料还是开放的大规模词向量语料,词级CNN模型整体好于字符级CNN模型,F1均值提升范围约1%~3%。字符级和词级语言模型的区别在于字符级或者词级的文本信息作为CNN模型的最小处理单元。对于能源政策文本通常具备较强的行文规范以及上下文之间具备较强的语义关系,从语义空间的角度,词级语言模型能够更好地表达文本中的语法和上下文语义关系,然后能够基于CNN模型去进一步放大词向量的语义表达能力,而字符级语言模型以单个字符进行处理时丢弃了词所具备的语义信息,因此对于能源政策文本采用词级CNN模型能够达到更好的分类效果[27]。另一方面实验观察到从全文的角度采用自定义词向量的词级CNN模型使用特定领域内的语料进行训练,对同领域的文本分类效果有一定的提升,但当语料扩大到100M以上时,词级CNN模型的分类效果差异较小,为0.22%。
| 图表编号 | XD00140434500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 杨锐、陈伟、何涛、张敏、李蕊伶、岳芳 |
| 绘制单位 | 中国科学院武汉文献情报中心、科技大数据湖北省重点实验室、中国科学院武汉文献情报中心、科技大数据湖北省重点实验室、中国科学院大学经济与管理学院、海军工程大学信息安全系、中国科学院武汉文献情报中心、科技大数据湖北省重点实验室、中国科学院武汉文献情报中心、科技大数据湖北省重点实验室、中国科学院武汉文献情报中心、科技大数据湖北省重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}