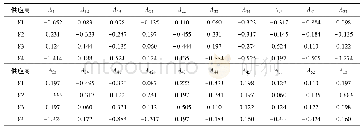
《表2 不同输入下的前景检测结果的F测度值比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
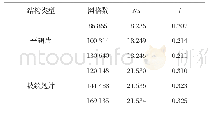
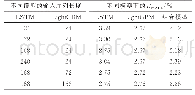
为了验证多输入的方法对前景检测的有效性,同时测试以连续的3个视频帧作为输入是否会损失长程信息,本小节设置了对比实验:分别以1帧、3帧、5帧作为网络输入,采用在VGG16[11]上预训练好的参数作为初始化权重,比较它们的前景检测结果.图3给出了不同的输入分别在3种场景下的视觉质量结果.从结果图中可以看出,多帧输入(图3(d)和(e))的前景检测结果更加接近真值图,能够保持较为准确的轮廓信息.单帧输入的结果则较为逊色,甚至在highway这个场景下没有检测出右上角运动的汽车,这是因为将多种视频场景混合在一起训练时,网络无法从一张图像中准确地判断出哪个物体是运动的,哪个物体是静止的,所以网络只能大致判断出图像中的显著性物体.从图中还可以看出,3帧输入和5帧输入的结果差别并不明显,但是在office这个场景中,5帧输入的结果没有3帧的好,这是因为增加的视频帧与当前帧相关性并不大,从而引入了一些不必要的误差,由此可以得出,网络的输入并不是越多越好.对比实验的量化结果如表2所示,多输入的F测度值十分接近,而3帧输入的平均F测度值最高,从而进一步验证了本文所提方法的有效性.
| 图表编号 | XD00138592200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.15 |
| 作者 | 杨敬钰、师雯、李坤、宋晓林、岳焕景 |
| 绘制单位 | 天津大学电气自动化与信息工程学院、天津大学电气自动化与信息工程学院、天津大学计算机科学与技术学院、天津大学电气自动化与信息工程学院、天津大学电气自动化与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}