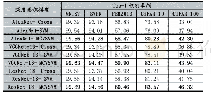
《表2 深度模型在CK+数据集识别准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
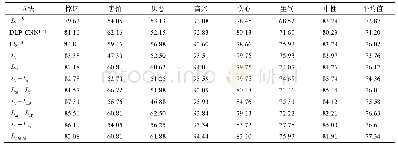
深度学习在表情识别中的应用,大多基于VGGNet、GooGleNet与ResNet网络模型,其核心结构均为深度卷积神经网络(Deep convolution neural networks,DCNN)。在此基础上,Mollahosseini等[53]将AlexNet与GoogleNet模型结合,构建了一个7层CNN用于人脸表情识别,得到了较好的识别效果。Jung等[54]提出利用彩色图像与人脸特征点联合训练CNN网络,其网络包括3个卷积层与2个隐藏层,但这使得其表情特征学习不够精确。Lopes等[55]将部分特定特征提取方法与卷积神经网络进行组合,先采用预处理技术提取部分特定表情特征,但这会导致未知环境下正确率不高、鲁棒性不足。Verma等[56]提出了一个具有视觉和面部标识分支的网络,其视觉分支负责图像序列的输入,并引入从低层到高层的跳转连接,以此考虑到底层特征的重要性;面部标识分支研究面部标记轨迹,考虑到因面部大动作造成的面部特征的变化,如眼睛、鼻子、嘴唇的动作变化等,该方法在CK+数据集上取得了较高的识别率。表2对几种深度模型在CK+数据集上的识别准确率进行了比较。
| 图表编号 | XD00138091900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 叶继华、祝锦泰、江爱文、李汉曦、左家莉 |
| 绘制单位 | 江西师范大学计算机信息工程学院、江西师范大学计算机信息工程学院、江西师范大学计算机信息工程学院、江西师范大学计算机信息工程学院、江西师范大学计算机信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}