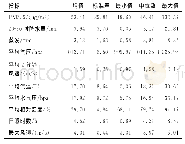
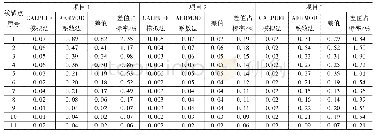
《表2 PM2.5浓度预测的模型成分比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于深度学习的PM_(2.5)多模态集成预测应用》
注:加粗的数字表示最优结果
利用以上评价指标,本文验证VMD-ELSTM-GS模型的有效性,探讨模型各个成分的作用。具体来讲,本文将VMD-ELSTM-GS模型与相关联的EMD-ELSTM-GS、EMD-LSTM-GS两个“分解-集成”模型,以及与ELSTM-GS、LSTM-GS、LSTM三个单一模型进行对比。需要说明的是,由于单一模型的预测效果很大程度上会受到模型参数和超参数的影响,故用于比较的ELSTM-GS和LSTM-GS的参数、超参数与各“分解-集成”模型保持一致,都是由GS确定的优化参数。LSTM是无GS优化的网络,LSTM的优化参数包括样本数、节点数、迭代次数、批量大小和时间步。样本数与窗宽保持一致,节点数的范围为[30,70],迭代次数的设置是以探针法确定的范围[50,150],批量大小为样本数的倍数,范围为[120,210],时间步为1(隔日预测)。经网格搜索,LSTM-GS选定为[输入样本数,节点数,迭代次数,批量大小,时间步]=[30,50,100,200,1]。原始的LSTM的参数设置为[输入样本数,节点数,迭代次数,批量大小,时间步]=[30,x,y,z,1]。弹网惩罚系数的经验范围为[0,0.1],经探测最优参数范围为[0.005,0.015],通过设置步长为0.001的学习率逐步搜索,我们选定ELSTM的弹网惩罚优化系数为[0.01,0.01]。表2是利用不同的模型成分对兰州和南京预测结果进行的精度比较。
| 图表编号 | XD00137622600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.25 |
| 作者 | 黄恒君、王伟科 |
| 绘制单位 | 兰州财经大学统计学院、兰州财经大学统计学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}