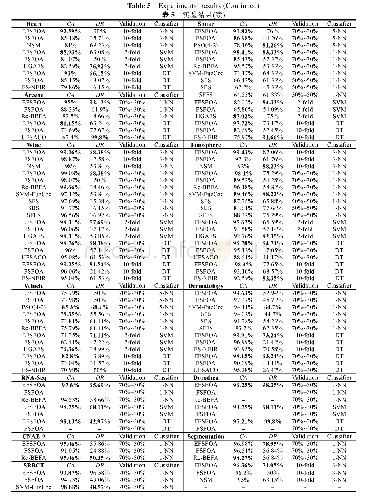
《表2 指标筛选结果:区域尺度农业管理分区的无监督特征选择与破碎度优化算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《区域尺度农业管理分区的无监督特征选择与破碎度优化算法》
注:最大方差法与拉普拉斯得分法行的数字为该列指标被选择的优先级顺序,1为最高优先级,没有数字则未被选中。FSCC行中,0代表该列指标作为中心点被选中,字母表示该列指标所属簇的组别编号。
3种方法各尺度下的指标筛选结果见表2:累积降水量与平均降水量、累积有效日照时长与平均气温日较差、AK与pH值、TN与OM常属同簇。平均降水量的计算基于累积降水量和当年生育期天数,相关研究显示日照与温度有一定的相关性[48]、pH值与土壤速效钾含量极显著相关[49]、土壤有机质含量与土壤总氮量间呈正相关[50],体现FSCC对冗余环境要素有效判断、分类的能力;如皋、南通、江苏等地势低平,坡向,高程和坡度等相关性较高地形指标各分辨率下均划分为同簇,地形复杂多变的冬小麦主产区则分为不同簇,反映FSCC对地形指标的划分与区域客观地形地貌的变化相吻合。可见,FSCC从同簇高相关性指标中挑选簇中心指标,剔除冗余指标,降低了重要指标被误筛的概率,表现出具有提取表达部分指标间相关性以及指标与对应客观环境间联系的能力。
| 图表编号 | XD00135770400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 黄芬、朱金诚、张小虎、刘通宇、朱艳 |
| 绘制单位 | 南京农业大学信息科学与技术学院、南京农业大学国家信息农业工程技术中心、南京农业大学信息科学与技术学院、南京农业大学国家信息农业工程技术中心、南京农业大学信息科学与技术学院、南京农业大学国家信息农业工程技术中心 |
| 更多格式 | 高清、无水印(增值服务) |

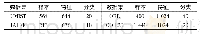

{kind=link}