《表2 聚类准确率对比:基于正则互表示的无监督特征选择方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
单位:%
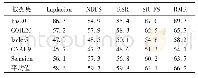
图1是RMR方法计算出的Iris20特征权重直方图,横轴代表Iris20数据集的20个特征,纵轴代表计算出的各个特征的权重。权重越大,特征越重要,越具有代表性。从图1可以直观地看出,前4个特征的权重明显大于后16个特征的权重,这说明RMR方法可以有效地识别出数据集中具有代表性的特征。从表2的实验结果数据可以得知,RMR特征选择方法与其他四种特征选择方法相比,其在5个标准数据集上选出的特征子集的平均聚类准确率最大,说明RMR方法对聚类准确率的提升能力更强。从表3的实验结果数据可以看出,RMR方法选出的特征子集的归一化互信息NMI值最大,说明RMR方法选出的特征子集的聚类效果更好。无论是聚类准确率还是归一化互信息,都是度量聚类结果好坏的常用指标,值越大越好。因此从表2和表3可以得出相同的结论,使用RMR方法对原始数据集进行特征选择,可以选出数据中的具有代表性的特征,有效地改善数据在聚类时的表现,并且同其他四种对比方法相比效果更好。
| 图表编号 | XD00163199300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.10 |
| 作者 | 汪志远、降爱莲、奥斯曼·穆罕默德 |
| 绘制单位 | 太原理工大学信息与计算机学院、太原理工大学信息与计算机学院、太原理工大学信息与计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}