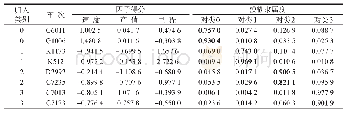
《表1 司机聚类准确性示例》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
其中:ni为司机i行驶的总趟数;Cl为分类结果;nicl为第Cl类中该司机的行车趟数;max{nicl}表示该司机行驶记录最多的趟数聚到某类中的数量。理想状态下,单个司机的驾驶记录都会分到一个类中,那么max{nicl}/ni=1;m为司机总数。最终对所有司机的分类准确性计算均值,得到平均分类准确性,司机聚类准确性示例如表1所示。从表1可得,司机1仅驾驶了车1,这三趟驾驶行为差异较小,均被分到类1中,那么该司机的分类准确性为100%。司机2驾驶过车2和车3,驾驶两辆车行为差异不大,司机2的所有记录都分到了类2,分类准确性为100%。司机3驾驶过车4和车5,驾驶车4的三趟记录分到了类1,驾驶车5的两趟记录分到了类2,分类准确性为3/5×100%=60%。最终得到的3个司机的平均分类准确性为(100%+100%+60%)/3=86.67%。为了对比上述方法的优缺点,本文设置聚类簇的个数为3,采用K-means算法对划分好的趟数据进行聚类分析,得到K-means算法的结果。根据同样的分类准确性验证方法,验算K-means算法计算的平均准确性为75%,而Blondel算法在阈值确定的情况下准确率为92.5%,相比K-means算法准确率明显提高。
| 图表编号 | XD00134612100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 吴行斌、郭强、张林兵、梁耀洲、刘建国 |
| 绘制单位 | 上海理工大学复杂系统科学研究中心、上海理工大学复杂系统科学研究中心、上海理工大学复杂系统科学研究中心、上海理工大学复杂系统科学研究中心、上海财经大学会计学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}