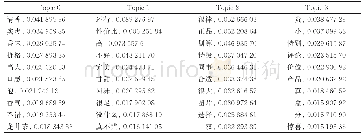
《表3 LDA和Doc_LDA得到的部分主题》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于LDA模型和Doc2vec的学术摘要聚类方法》
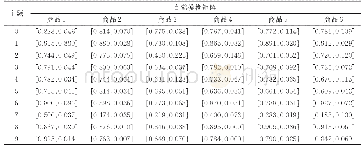
表2左侧是语料集经过LDA训练后得到的主题分布,设定topic=50,可以得到它有5个相关主题,分别是7、12、14、31、43,其他主题概率为0的认为是不相关主题。表2右侧是通过新模型训练得到的主题间距离分布,加黑数据是与左侧列出主题的相关主题。第一项值是主题标号,第二项是主题间的距离,由表2得,所有主题分布的平均距离为2.077,最小距离分布为1.01,而LDA模型得到的5个相关主题在表2右侧中的距离分布均小于平均值。可以看出,LDA在新模型训练过程中依然保留了原本的特征信息;同时可以得到,在经过Doc-LDA模型后得到的距离分布中,例如主题43和主题36分别是最短和最长距离。由于左侧LDA得到的相关主题中,主题12的概率最高,因此,将左侧的主题12,右侧的主题43、36分别列出得到表3。主题12的主题词“嵌入式”、“数控系统”、“芯片”和主题43中的主题词“单片机”、“FPGA”、“可编程”等具有较高的相关性,通过LDA模型训练出的主题分布中缺少了主题43,而主题36中“计算机技术”、“预测”、“ATA”等虽都是计算机类下的主题词语,与主题12间的相关性较差,对应于表2右侧中有最远的距离分布为3.08。
| 图表编号 | XD00133688300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.15 |
| 作者 | 张卫卫、胡亚琦、翟广宇、刘志鹏 |
| 绘制单位 | 兰州交通大学电子与信息工程学院、兰州交通大学电子与信息工程学院、兰州理工大学经济管理学院、兰州交通大学电子与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}