《表2 LibriSpeech数据集的词错误率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了进一步验证改进GRU模型在大数据集上的实际表现,实验提取fMLLR特征在LibriSpeech 100 h纯净语音数据集上进行测试,网络结构和参数配置与TIMIT数据集相同。实验结果如表2所示,词错误率的变化趋势与在TIMIT数据集上观察到结果保持一致,证实了改进模型的有效性。
| 图表编号 | XD00129806900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 俞建强、颜雁、刘葳、孙一鸣 |
| 绘制单位 | 长春理工大学计算机科学技术学院、长春理工大学计算机科学技术学院、长春理工大学计算机科学技术学院、长春理工大学计算机科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |
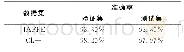




{kind=link}