《表2 模型精度评价:基于随机森林与地统计预测城市土壤PAHs分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
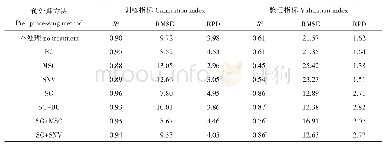
观察模型评价的4个指标(表2),从ME和R2数值上看随机森林模型显示出最好的预测精度;而MAE和RMSE在数值上显示RFerr+K模型是最好的预测模型.ME表示预测结果随机误差的平均值,由于随机森林模型在预测低值区和高值区时存在系统性偏差,即存在低值区被高估和高值区被低估的现象.对于南京地区来说当土壤多环芳烃均值为750μg/kg[32],环境变量对其无法进一步精确区分;当高值大于4800μg/kg时,受样点数影响,机器学习效果较差(图4b).因此ME不能说明随机森林模型比RFerr+K模型精度更高.R2是预测值回归平方和与总离差平方和之比,反映了自变量对因变量的解释程度,R2接近于1,观察点在回归直线附近越密集.由于随机森林模型在PAHs含量中值区预测效果很好,因此R2较高.但是随机森林在低值区和高值区预测存在偏向相反的系统性误差,虽然整体上R2显示回归拟合较好,但是不能认定其精度更高,还需要结合样点总体空间分布预测精度进行判断.
| 图表编号 | XD00127681300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.20 |
| 作者 | 李富富、陈东湘、王院民、颜道浩、吴绍华 |
| 绘制单位 | 南京大学地理与海洋科学学院、浙江财经大学东方学院、南京大学地理与海洋科学学院、南京大学地理与海洋科学学院、浙江财经大学土地与城乡发展研究院、国土资源部城市土地资源监测与仿真重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}