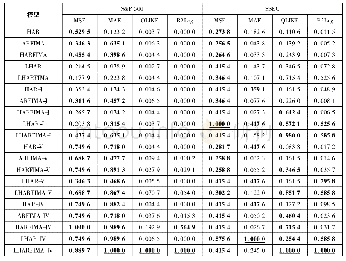
《表7 样本量50 000时的LSTM模型实验》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《不同深度学习模型的科技论文摘要语步识别效果对比研究》
样本量为10 000时,经过13次迭代,LSTM模型达到最佳实验效果,获得了0.7825的平均F1值,效果不如支持向量机实验。将样本量调整至50 000,实验结果如表7所示。
| 图表编号 | XD00125928800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.25 |
| 作者 | 张智雄、刘欢、丁良萍、吴朋民、于改红 |
| 绘制单位 | 中国科学院文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系、中国科学院武汉文献情报中心、科技大数据湖北省重点实验室、中国科学院文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系、科技大数据湖北省重点实验室、中国科学院文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系、科技大数据湖北省重点实验室、中国科学院文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系、中国科学院文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}