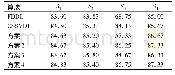
《表2 算法在GT库上的实验结果(错误率/%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
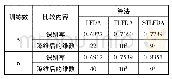
GT数据库包含50个人的面部图像,每个人都有15幅背景复杂的彩色图像。图像由不同表情、不同光照条件和不同角度的正面人脸构成。我们移动每个图像的背景,并将它们转换成灰度图像。为了方便后续差异字典的图像提取,在实验中将训练样本、测试样本以及差异样本全都缩放为34×34的灰度像素矩阵。实验中,以GT库每人前1、2、3幅图像及其灰度对称脸为训练样本,GT库中除训练样本以外的图像为测试样本。取ORL库的前25类构成差异字典,每类的第1张图像为差异字典的基准样本,第2、4、5、8张图像为差异字典的差异样本,λ=0.3,β=0.5。表2是对比算法和本文算法在GT库上的实验结果,以错误率的形式表示。
| 图表编号 | XD00122856500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.16 |
| 作者 | 邓佳璐、贾玉洁、卫祥、杨波、阎石 |
| 绘制单位 | 兰州大学信息科学与工程学院、兰州大学信息科学与工程学院、国网甘肃省电力公司信息通信公司、国网甘肃省电力公司信息通信公司、兰州大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}