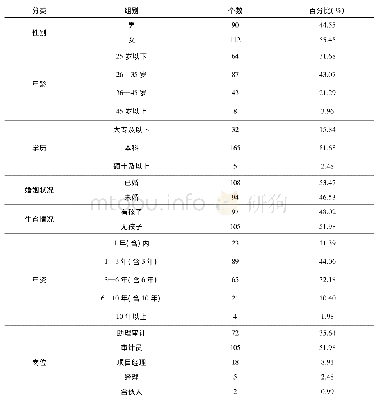
《表1 2012-2014两轮调查间非流失和流失样本的特征分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
我们的分析需要将样本限定在2012、2014两轮调查中变量均不缺失的样本基础上,有效的样本量为21,457。而2012年的有效个人样本在2014年追踪访问时有些被成功访问(追踪样本),而其他样本由于家户搬迁、拒访、死亡等各种原因没有被成功访问到(流失样本)。追踪样本和流失样本之间通常存在着系统的差异。为了降低由于选择性的样本流失所造成的分析结果偏误,我们采用逻辑斯蒂模型估计样本的流失概率。在这个逻辑斯蒂模型中,我们加入了一系列地区(居住地、城乡属性、社区类型)、家庭(家庭收入、房产)、个体(年龄、性别、婚姻状态、工作状态、健康状况、认知功能、调查时的配合度等)层面的变量来预测样本的流失概率。我们基于这个概率计算了逆概率权数,在针对面板数据进行的分析中我们将利用这个权数对于分析样本进行加权(Vandecasteele&Debels,2006)。
| 图表编号 | XD00122416800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.29 |
| 作者 | 吴琼、张沛康 |
| 绘制单位 | 北京大学中国社会科学调查中心、北京大学教育学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}