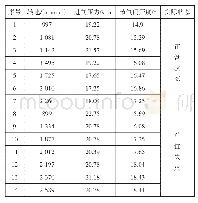
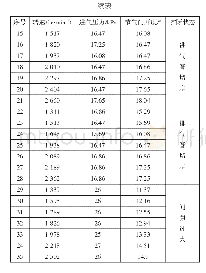
《表2 样本筛选前后的神经网络训练时间、正确率对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
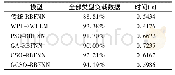
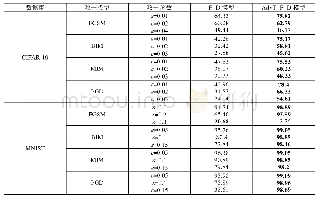
实验2将选取的不同样本通过神经网络算法进行比较,该实验采用了4层BP神经网络作为分类器,包括输入层、2层隐层和输出层,根据经验值对各隐层节点数进行了设置。第1层隐层节点数设置为了输入层与输出层节点数总和的50%,第2层隐层节点数则设置为了第1层隐层节点数与输出层节点数总和的50%。其中,BP网络的训练精度为0.01,学习率为0.01,最大迭代次数为5 000,并且设置过拟合检测次数为100。本文采用每句话的分类统计结果来对说话人进行识别,即统计每句话转化为声纹特征后,对每句话中各个样本特征的分类识别结果进行统计,每句话中出现最多的分类结果作为对该句话的最终识别结果。由于BP网络的训练结果的随机性,本文对每种特征分别进行了10次训练和测试,对各特征的识别结果进行了统计,最终的识别结果表2所示。从表可见,AP聚类能够有效的压缩数据,极大地降低训练成本并节约训练时间,且能有效地发现说话人的本质特征,其聚类前后的说话人识别的准确率无本质差异。
| 图表编号 | XD00115517300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.20 |
| 作者 | 张辰、张华、高宁化、陈豪 |
| 绘制单位 | 西南科技大学信息工程学院特殊环境机器人技术四川省重点实验室、西南科技大学信息工程学院特殊环境机器人技术四川省重点实验室、西南科技大学信息工程学院特殊环境机器人技术四川省重点实验室、西南科技大学信息工程学院特殊环境机器人技术四川省重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}