《表2 数据收集编码样例:数字档案资源整合与服务过程中的隐性知识分类——以赋能思维为视角》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《数字档案资源整合与服务过程中的隐性知识分类——以赋能思维为视角》
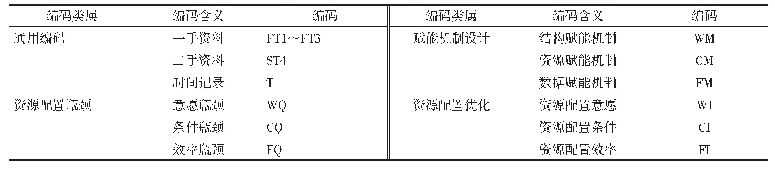
数据分析阶段对收集的定性数据进行编码,对形成的概念进行代码标识(见表2)。首先将调研或访谈过程中获得的录音整理成文字,然后遵从Straussian扎根理论的系统化编码程序进行数据编码流程。第一步,相似主题聚拢组合。将同一文档中的相似主题/代码的资料,聚拢和发掘其属性,赋予概念,然后再以新的方式重新组合起来;第二步,多个代码/范畴聚拢。将其形成一个具有层次结构、流程结构和关联关系层级关系;第三步,挖掘核心范畴。发掘出能将所有范畴聚拢成核心的核心范畴,及能将其他所有范畴贯穿而形成一条“故事线”的范畴。采用NVivo软件对庞杂的质性数据进行编码分析,辅助管理定性数据,并挖掘数据中潜在的规律。同时该软件提供建模工具,支持概念图形式展示研究结果。
| 图表编号 | XD00115310300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.25 |
| 作者 | 陈慧、王晓晓、南梦洁、安小米 |
| 绘制单位 | 华中师范大学信息管理学院、华中师范大学信息管理学院、华中师范大学信息管理学院、中国人民大学信息资源管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}