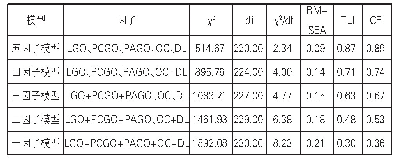
《表1 模型拟合指标:基于验证因子分析的校本英语分级测试效度研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
将数据导入预设的5个模型进行参数估计,得到各项拟合指标见表1。表1最后一行是各个拟合指标的临界值参考标准。从5个模型的拟合指标看,模型4无法拟合,直接排除。模型3各项指标均在临界范围之外,即数据和模型拟合不良,数据无法支持理论假设,也被排除。模型1除PNFI指标外,其他均较为理想,但该模型的一个误差变量为负值(e1=-19.451),这属于模型违反估计,即Heywood案例[24]38,因而也应被排除。模型2的RMSEA指标略高于临界值,但其他指标均符合标准,可以作为备选模型。模型5各方面指标均符合临界参考值,且相对优于模型2。此外根据刘恒超等的方法[23],通过卡方检验,发现模型2和模型5之间在0.05水平上存在显著差异(?χ2=28.155,?df=1),因此最终将模型5确定为最优模型。
| 图表编号 | XD00108325800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 邵健 |
| 绘制单位 | 浙江工商职业技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}