《表2 模型内在结构拟合度指标》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:***代表P<0.001。
根据表2,各个观察变量的因子负荷值在0.519~0.903之间,均高于0.5的临界标准,且所有观察变量均通过了路径显著性检验(p<0.001),因而从观察变量的角度看,每个观察变量均能反映各自要测量和表达的构念。然而,从因子负荷值看,阅读维度的3个观察变量对潜变量的解释力最小,听说维度观察变量对潜变量的解释力最强。接下来,依据组合信度和平均方差提取量对维度的整体效度进行评价,3个维度的组合信度均在临界值以上,整体较为理想。在平均方差提取量指标上,阅读维度取值为0.3501,低于0.5的临界标准,这说明测量误差对观察变量变异的解释量高于阅读潜变量对观察变量的解释量,也就是说,阅读测试部分可能存在较大的测量误差。这是因为相比于写作和听说口试,阅读部分涉及的题目更多,题目类型也更加复杂。以阅读测试中常见的单选题为例,此类题目存在一定的猜题概率,而其他客观题(如对错判断题)也或多或少存在同样的问题。同时,测量模型中观察变量数目越多,测量误差就有可能越大。例如孔文等以验证因子分析法检验阅读能力二分说[14],采用了每个题项的原始分作为测量变量,发现2个维度上各个因子负荷值在0.27~0.5之间,而低因子负荷值必然导致组合信度和平均方差提取量随之降低。因此,与其他维度相比,阅读维度的效度指标相对较低也就不难理解了。由于仅有一个维度的一个指标低于临界标准,可以认为该模型的构念效度指标良好,模型内部质量较佳。
| 图表编号 | XD00108325500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 邵健 |
| 绘制单位 | 浙江工商职业技术学院 |
| 更多格式 | 高清、无水印(增值服务) |

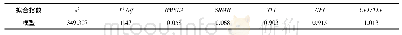




{kind=link}