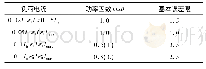
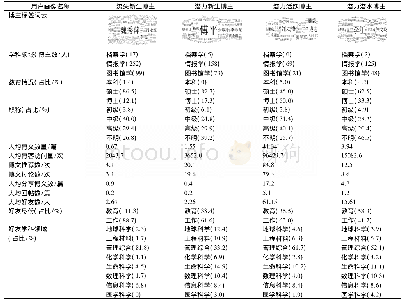
《表1 编级生信息表:基于K-means算法的高校编级生群体画像研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
数据清洗的主要任务是筛选与实验目标相关的数据,本实验将筛选适于聚类实验的编级生名单、课程记录和高考记录,同时去除重复项,保持唯一性。表BST中包含2014-2018学年间所有编级生,含2010级、2011级学生。2012年,A校迁址,学生生源和教学环境发生变化。为保证实验对象一致性,本项目选取2016-2018年编级生群体为实验对象,共385人次,其中存在69例2次及以上编级,1例同名状况,删除重复项后共计317人,创建表SYBST(如表1所示)。未通过课程记录和高考成绩记录筛选将以2016-2018学年间的317名学生为中心展开。
| 图表编号 | XD00108158500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.25 |
| 作者 | 王斌、曹杨、卞文献 |
| 绘制单位 | 南京邮电大学通达学院、南京邮电大学通达学院、南京邮电大学通达学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}