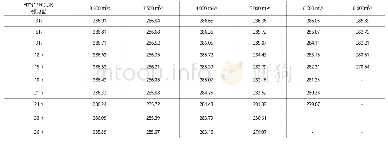
《表2 各个规模下LSD、ML与AL最大/平均降低百分比统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证优化后结构在Cache访问均衡性方面的表现,我们收集了不同规模下(16/32/64核)程序运行过程中的Cache访问报文延迟,并分别统计了报文延迟的LSD、ML和AL相比于优化前降低的比例,如图12所示.其中,各个规模下LSD、ML与AL的最大/平均性能提升如表2所示.相比于优化前,优化后的结构在三项指标上在不同规模下都得到了一定程度的降低.优化后的结构在16/32/64核规模下在LSD上分别平均降低了0.7%/7.7%/19.6%,在ML上分别平均降低了2.9%/11.6%/12.8%,在AL上分别平均降低了0.9%/2.0%/6.4%.其中LSD的降低表明Cache访问报文延迟之间的差异性缩小,而ML的降低表明制约系统性能的瓶颈延迟变小,进而能够促进系统性能得到提升.但在小规模(16核)结构下,系统在这三项指标上的改善并不明显,甚至在ML指标上对于某些应用程序出现了小幅度上升(bodytrack和ferret).这是因为在规模较小的时候Cache访问报文延迟之间的差异性较小,因此Cache访问均衡性问题并不如规模大时明显,从而限制了优化效果.但随着规模的不断增大,优化的效果随之增强,这得益于在规模增大时Cache访问均衡性的问题逐渐凸显.因此可以预见当规模继续增长时,本文设计在均衡性上的优化效果将更加明显.
| 图表编号 | XD00107157200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 王子聪、陈小文、郭阳 |
| 绘制单位 | 国防科技大学计算机学院、国防科技大学计算机学院、国防科技大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}