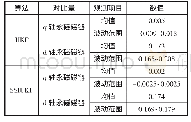
《表7 4种算法实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:表格内数值表示对应算法重复1000次后取平均的正确率,括号内数值表示方差;第1组为抽样前:A(40)、B(29)、C(5),第2组为C类抽样200%、抽样后:A(40)、B(29)、C(15),第3组为C类抽样300%、抽样后:A(40)、B(29)、C(20),第4组为C类抽样400%、抽样后:A(40)、
为了比较不同机器学习方法的优劣性,首先采用十折交叉验证方式得到各方法的平均正确率,在此基础上,各自重复1000次后取平均得到各方法下的正确率,即针对每种算法分别进行了10000次正确率计算后取平均。为了同传统计量方法及其他机器学习方法作对比,加入多项Logit回归及支持向量机、随机森林等方法分别建立模型。其中支持向量机采用Gauss径向基函数;贝叶斯网络方法采用K2算法进行结构学习,经过反复比较模型正确率及标准差,最终确定贝叶斯网络建模中的最大父节点数为1,即所建贝叶斯网络为朴素贝叶斯网络,所有变量的父节点均为类标签,所建贝叶斯网络图如图1所示。 (以上操作均在WEKA3.6.10上实现,最终结果见表7)
| 图表编号 | XD0010676200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.11.25 |
| 作者 | 聂瑞华、石洪波 |
| 绘制单位 | 山西财经大学统计学院、山西财经大学信息与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}