《表4 小样本(n1,n2,N1,N2)=(20,20,30,30)下犯第一类错误的概率(显著性水平α=0.05)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
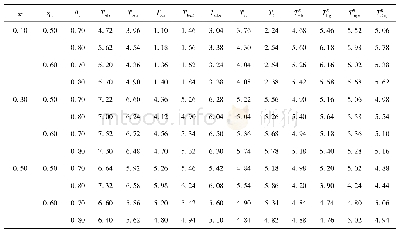
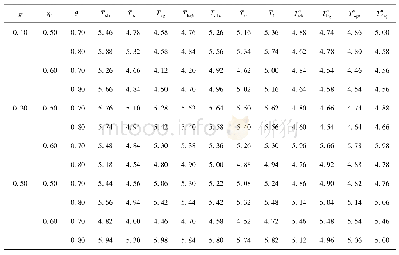
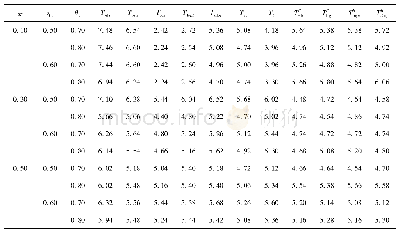
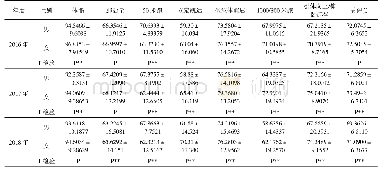
在不同的样本量设置下,考察犯第一类错误的概率时考虑了如下参数设置:π1=0.1(0.2)0.5,η1=0.5(0.1)0.7,θ1=0.7(0.1)0.9,η2=η1+0.05,θ2=θ1+0.05,即考虑了3(π1的值)×3(η1(η2)的值)×3(θ1(θ2)的值)=27种参数组合。对于检验功效考虑了:δ=0.1(0.01)0.3,π1=0.1(0.2)0.5,(η1,θ1)=(0.5,0.7),(0.6,0.8),(0.7,0.9),η2,θ2同以上设置,即考虑了3(δ的值)×3(π1的值)×3((η1,θ1)的值)=27种参数组合。这里的a(b)c表示取值是从a以步长b变化到c。在每个样本量设置和每种参数设置下,随机产生5 000组数据m={(n11j,n10j,n01j,n00j,xj,yj):j=1,2},在显著性水平α=0.05下,对于每个检验统计量Ti(i=w1,w2,sc,l,tan1,tan2),其犯第一类错误的概率可通过以下公式计算:基于统计量Ti拒绝原假设的次数/5 000(δ=0),经验功效通过以下公式计算基于统计量Ti拒绝原假设的次数/5 000(δ≠0)。犯第一类错误概率的模拟结果见表4~7。由于篇幅的限制,只列出了小样本和中等样本下的部分功效的模拟结果,见表8~9。
| 图表编号 | XD00100241000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.15 |
| 作者 | 邱世芳、何杰 |
| 绘制单位 | 重庆理工大学理学院、重庆理工大学理学院 |
| 更多格式 | 高清、无水印(增值服务) |
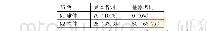

{kind=link}