《表3 英文数据集上不同算法抽取出的关键词》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
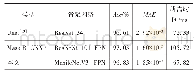
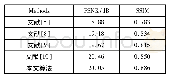
本文将4种特征提取方法得到的特征词典在文本分类任务上进行对比,以此来验证本文方法得到的特征词典的准确性.以处理后的软件工程和通信安全为例,选取前10个词为例,如表2和表3给出了不同算法分别在中英文数据集上抽取出的特征词项.可以看出,KEGS方法得到的特征词典由于未考虑语义信息,效果较差,并不能代表短文本类别特征.KES方法和TK G2|W1|cc算法将词项表示为文本图形式但却都忽略了文档本身所携带的结构属性因素,得到的结果也有待提升.由此可以证明词项之间的语义信息与词语本身的属性特征均不容忽视.显然,本文算法充分考虑了词语间的隐含语义并综合考虑了文本图自身的结构特征,得到的结果相比之下更为合理.
| 图表编号 | XD0096849900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 马慧芳、刘晓倩、马兰、伍诗萌 |
| 绘制单位 | 西北师范大学计算机科学与工程学院、桂林电子科技大学广西可信软件重点实验室、西北师范大学计算机科学与工程学院、西北师范大学计算机科学与工程学院、西北师范大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}