《表3 不同网络设计在CarSeries上的识别精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
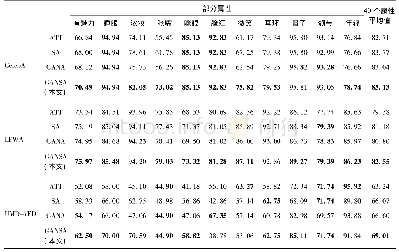
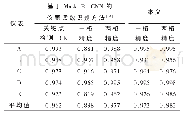
分析表3可知,对比OneNet_Random和OneNet_PreTrain可知,使用相似数据集上预训练的模型,通过微调,可将其中可用的知识迁移出来,从而在卡口车型数据集较小的时候,能大幅度提高车型识别的准确率,提升了近8%。对比OneNet_PreTrain和DoubleNet的可知,显然度量损失函数可以帮助提高Softmax分类的效果,特别是在样本数据比较少的时候,提升了近2%。分析图5的图可知,由于OneNet_Random的权重是随机初始化的,训练准确率随着时间线性增加,而验证准确率在第15个epoch时就开始达到最大值,开始上下波动,这也就意味数量小非常容易产生过拟合现象。对比OneNet_PreTrain和DoubleNet的准确率曲线可知,DoubleNet的曲线波动比较平缓,而且准确率提升更高,说明度量损失函数可以帮助模型学习到更加泛化的特征。
| 图表编号 | XD0096239700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.25 |
| 作者 | 王静、黄振杰、王涛 |
| 绘制单位 | 广东工业大学自动化学院、广东工业大学自动化学院、广东工业大学自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |

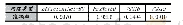


{kind=link}