《表4 面板数据回归结果:中国高技术制造业转型升级的优势依托——基于综合优势战略论的实证分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《中国高技术制造业转型升级的优势依托——基于综合优势战略论的实证分析》
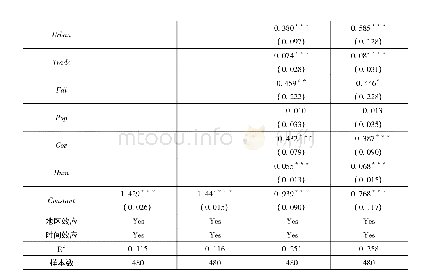
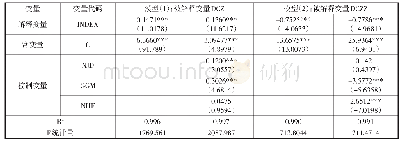
注:表中圆括号内的数字为回归系数标准差,方括号内的数字为P值;*、**、***分别表示在10%、5%、1%的水平上显著,AR(1)和AR(2)分别表示差分残差项一阶和二阶序列相关的P值,Sargan为过度识别检验
基于综合优势原则,本文使用Stata15.0软件对2000—2017年我国30个省、市、自治区的面板数据进行实证分析。面板数据模型估计主要包括最小二乘法(OLS)、固定效应模型(FE)和随机效应模型(RE)三类,具体采用哪种模型需要根据F检验、拉格朗日乘数检验和Hausman检验结果来确定。表4中的列(1)、(2)、(3)分别给出了OLS、FE、RE模型的回归结果。可以看出,面板数据F检验统计量的值为67.44,相应的P值为0.000 0,检验结果显著拒绝了原假设,说明在OLS与固定效应模型的比较中应选择固定效应模型。拉格朗日乘数检验统计量的值为chi2(8)=62.98,相应的P值为0.000 0,显著拒绝了原假设,说明在混合OLS与随机效应模型的比较中应选择随机效应模型。Hausman检验统计量的值为chi2(8)=32.71,相应的P值为0.000 1,显著拒绝了原假设,说明在固定效应模型与随机效应模型的比较中应选择固定效应模型。
| 图表编号 | XD0094309800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.28 |
| 作者 | 李国英、陆善勇 |
| 绘制单位 | 广西大学商学院、广西大学行健文理学院、广西大学商学院 |
| 更多格式 | 高清、无水印(增值服务) |

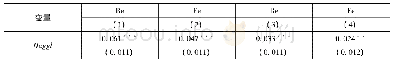


{kind=link}