《表3 不同基础题个数Q矩阵估计一致性》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
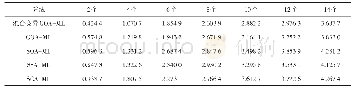
为进一步探讨CSE算法在实际应用中的效果,本研究使用该方法对K.K.Tatsuoka(1990)的分数减法数据进行分析,数据包含了536名学生在15个测验项目上的作答,测验考察了5个属性,测验Q矩阵改编自Missevy(1996)。该数据在之前的Q矩阵的估计和修正研究中均被使用(汪大勋等,2018;De Carlo,2012;de la Torre,2008)。根据原始作答数据和Q矩阵,使用DINA模型计算出各项目的鉴别度指数(item discrimination index,IDI;Lee,de la Torre&Park,2012)。将数据按IDI从高到低排列,分别选取前6、7、8、9、10题作为基础题,对剩余项目逐个进行估计。分析重新估计后的Q矩阵与原始Q矩阵的一致性程度,其中Q矩阵共有15×5=75个元素,计算相同元素的比例(括号内为相同元素个数),结果如下表。从表3可以看出,使用不同基础题个数,估计得到的Q矩阵与原始Q矩阵一致性程度差异不大,说明不同基础题个数下Q矩阵的估计结果趋于稳定。
| 图表编号 | XD009321900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 杨亚坤、朱仕浩、刘芯伶 |
| 绘制单位 | 金华教育学院、浙江师范大学教师教育学院、浙江师范大学教师教育学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}