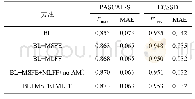
《表2 Charge-S上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
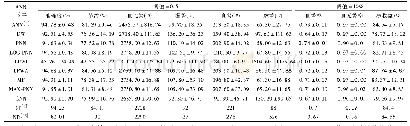
从表2~3的结果可以看出,本文提出的罪名预测模型GAC在两个数据集上均取得较好的预测效果。其F1union值相较于最优基线模型Bi-GRU-CNN,在Charge-S和Charge-L上分别提升了1.2%和1.4%。Bi-GRU-CNN模型未考虑词语语义之间的差异性,其粗略认为犯罪事实中所有词语的重要性一致或接近,而GAC模型使用注意力机制实现了各词语语义差异表示,该方式的语义表示更为准确。这表明了该模型可以在训练过程中准确捕获各罪名的类别关联性,并有利于提升罪名分类的准确率。
| 图表编号 | XD0091828600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 王加伟、张虎、谭红叶、王元龙、赵红燕、李茹 |
| 绘制单位 | 山西大学计算机与信息技术学院、山西大学计算机与信息技术学院、山西大学计算机与信息技术学院、山西大学计算机与信息技术学院、山西大学计算机与信息技术学院、太原科技大学计算机科学与技术学院、山西大学计算机与信息技术学院、山西大学计算智能与中文信息处理教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}