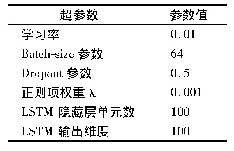
《表3 模型参数设置:融合语法规则的Bi-LSTM中文情感分类方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《融合语法规则的Bi-LSTM中文情感分类方法研究》
采用Glo Ve[24]工具进行词向量的训练,参考蔡慧萍等[25]的研究,认为高维度的词向量能够更精确地反映每个词在低维空间中的语义分布情况,每个词的语义信息也能够被充分表达。虽然使用维度更高的词向量维度可以更好地描述语义特征,但这也会造成Bi-LSTM神经网络模型参数显著增多,从而增大过拟合的风险。经过综合考虑,本文最终采用300维的词向量维度。Margin边界参数的作用是使训练出的分类器能更加准确地进行分类,参考Byrkjeland等[26]的研究,设定Margin参数为。设置窗口大小为8,其余参数采用初始值。模型采用AdaGrad[27]优化算法进行训练,具体参数设置如表3所示。
| 图表编号 | XD009078400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.25 |
| 作者 | 卢强、朱振方、徐富永、国强强 |
| 绘制单位 | 山东交通学院信息科学与电气工程学院、山东交通学院信息科学与电气工程学院、山东交通学院信息科学与电气工程学院、山东交通学院信息科学与电气工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}