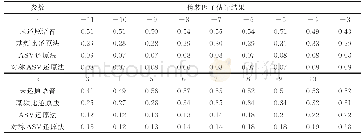
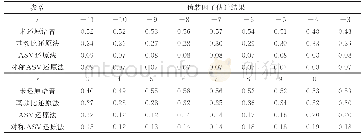
《表2 不同方法的变体词还原效果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由于得到的还原结果是一个排序,所以使用precise@k这个指标来评价变体词还原的效果。本文中precise@k=Nk/Q,对于每个变体词mi,将它对应的目标词emi在本文给出的排序序列出现的位置记做pi。Nk在所有的变体词测试样本中,pi≤k的变体词样本数量,Q为所有变体词测试样本数量。若p=1则说明得到的候选目标词排序列表的第一位即是真正的目标词,即准确还原了这个变体词。本文与目前效果最好的几种方法进行了比较,包括文献[8,9,12]的方法。本文中的方法记做AE-ECI。图4和表2展示了几种方法在数据集上的还原效果。从结果中可以看出,相比之前的方法,本文的方法在精确率上有一定的提升。对于pre@1,本方法相比效果最好的Zhang的方法提升3.41%,而对于pre@10,本文的方法较最好的Sha的方法提升了6.43%,显著提高了变体词还原效果。
| 图表编号 | XD0090289700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 游绩榕、沙灜、梁棋、王斌 |
| 绘制单位 | 中国科学院信息工程研究所第二研究室、中国科学院大学网络空间安全学院、中国科学院信息工程研究所第二研究室、中国科学院大学网络空间安全学院、中国科学院信息工程研究所第二研究室、中国科学院大学网络空间安全学院、中国科学院信息工程研究所第二研究室、中国科学院大学网络空间安全学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}