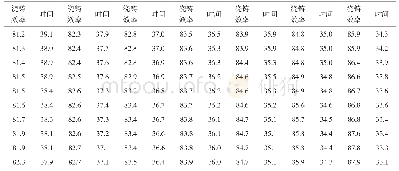
《表1 2 forest cover type数据集运行时间、SSE和A》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本实验的实现平台为MATLAB2014a。为了验证本文算法的聚类效果,与AKFCM、KFCM和FCM算法分别进行实验对比,通过AKFCM算法对流数据聚类时采用的随机采样法与本文差异性采样法进行对比,验证本文算法的聚类效果;通过与非采样的KFCM算法对比,验证本文算法的时间复杂度以及聚类效果;通过与FCM算法进行对比,验证本文算法的聚类效果优于传统聚类算法。由于KFCM算法是用数据集中所有数据构造核矩阵,所以选取的数据集不宜过大,避免存储空间不足。本文选用Movement-Libras整个数据集,MFCC数据集中20类中的部分数据,CIFAR-10数据集中20类中的部分数据,forest cover type数据集中7类中的部分数据来模拟流数据。表1为实验数据集。四个数据集的长度依次变大,目的是为了验证随着流数据规模的增加,本文算法的聚类效果不会受到影响,证明本文算法对于数据量大的流数据更具有优势。本文采用归一化互信息(NMI)[21]、运行时间、准确率(A)[22]及误差平方和(SSE)作为聚类效果的评价标准。为减少偶然误差,每次实验进行50次取平均值。
| 图表编号 | XD0090286100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 邱云飞、孙梦冉 |
| 绘制单位 | 辽宁工程技术大学软件学院、辽宁工程技术大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}