《表2 τ的不同取值下的运行时间》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
/ms
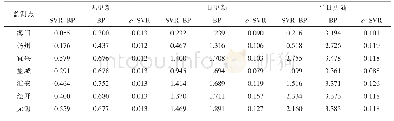
1) 参数τ的取值分析由η=exp(-γτ),τ∈{1,2,3,4,5}可知,τ越大,η越小;反之η越大。当近因值大于η时,将数据点划入到相应的类中,为了严格筛选核矩阵中的数据点,应尽量使η的值较大,但同时又会增加算法运行的时间,因此需要权衡时间复杂度与聚类效果之间的关系。表2~4分别为τ的取值对运行时间、NMI以及A的影响。Movement-Libras数据集的采样样本大小为100,MFCC数据集的采样样本大小为500,CIFAR-10数据集的采样样本大小为2 000,forest cover type数据集的采样样本大小为4 000。由表2可知,对于每个数据集,随着τ的增大,运行时间呈现不断增大的趋势,因此从运行时间上τ的值设为1较好;由表3可知,当τ=1时,四个数据集的NMI值都为最大,且随着τ值的增大,每个数据集NMI值降低较快;由表4可以看出,当τ=1时,四个数据集的A值都是最大的。因此实验中将τ值设为1。
| 图表编号 | XD0090285100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 邱云飞、孙梦冉 |
| 绘制单位 | 辽宁工程技术大学软件学院、辽宁工程技术大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}