《表2 四个数据分析应用及其数据规模》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
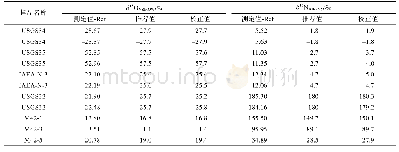
测试负载:使用Apach Spark来生成运行在YARN上的DAG作业。评估中使用的作业来源于如下数据分析应用:Word Count、TPC-H基准、迭代机器学习以及PageRank。如表2所示,对于每一类工作负载,数据集大小仿照真实生产环境的集群按比例缩放(Yahoo![8]和Facebook[10])。对于作业的分布,设置46%、40%和14%分别为小型、中型、大型的作业,这与实际应用中作业的分布相似[10]。
| 图表编号 | XD0090236300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.10 |
| 作者 | 李叶飞、徐超、许道强、邹云峰、张晓达、钱柱中 |
| 绘制单位 | 南京大学计算机科学与技术系、国网江苏省电力有限公司电力科学研究院、国网江苏省电力有限公司、国网江苏省电力有限公司电力科学研究院、南京大学计算机科学与技术系、南京大学计算机科学与技术系 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}