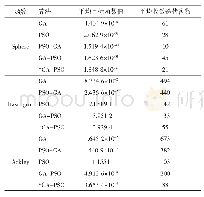
《表3 结合BN的CNN训练集部分迭代次数的损失函数值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表2和表3分别列出了当采用本文提出的基本CNN架构时,记录的不结合BN算法和结合BN算法的训练集部分迭代次数的损失函数值.从中可以看出,对于本实验的小样本数据源,在整个训练过程中,同等实验条件下,未采用BN算法的CNN架构,在第140次迭代时,损失值为0.053 4,从该观测点往后才最终收敛于0.035 7.而采用BN算法的CNN架构在迭代到第90次时,损失函数值就降到了0.029 3,从该观测点往后,损失函数值趋于稳定,最终150次时,收敛于0.011 2.其收敛速度明显优于未加BN算法的情况.结果再次验证了,当处理小样本数据时,采用BN算法的CNN架构可以有效解决训练过程中损失函数收敛速度慢的问题.
| 图表编号 | XD0089456500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.25 |
| 作者 | 何松华、张润民、欧建平、张军 |
| 绘制单位 | 湖南大学信息科学与工程学院、湖南大学信息科学与工程学院、国防科技大学ATR实验室、国防科技大学ATR实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}