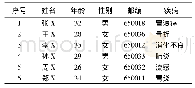
《表1 原始数据表:用于敏感属性保护的(θ,k)-匿名模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
例如,表1为原始数据表,经过(p,k)-匿名泛化后得到表2的匿名数据表(p=6,k=6).若攻击者已知被攻击者属于表2的等价类,由于该等价类中胃部疾病比例高达50%,因此攻击者可认为患者大概率患有胃部疾病,这种攻击称之为相似性攻击.若攻击者根据背景知识得知被攻击者患有骨科疾病,但不能明确具体的疾病值,根据表2中记录,由于只有骨折为骨科疾病,因此攻击者可推测出患者所患疾病为骨折,这种攻击称之为背景知识攻击.划分等价类时若记录敏感属性值语义相似的个数较多,等价类易受相似性攻击;若语义相似的个数较少,等价类易受背景知识攻击.对记录敏感属性值约束不足,导致数据表泛化后同时抵制两种攻击的性能不佳.本文提出(θ,k)-匿名保护模型,旨在通过分组优化模型的抗攻击性能.
| 图表编号 | XD0088376800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.15 |
| 作者 | 程楠楠、刘树波、熊星星、蔡朝晖、张家浩 |
| 绘制单位 | 武汉大学计算机学院、武汉大学计算机学院、武汉大学计算机学院、武汉大学计算机学院、武汉大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}