《表2 k-匿名数据:隐私保护技术在健康医疗大数据发布中的应用研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
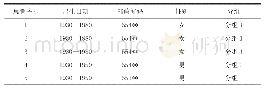
最流行的泛化模型为k匿名(k-anonymity)模型[5]。k匿名模型要求数据集中每条记录的准标识符属性集中包含与其他至少k-1个记录相同的值。满足k匿名的数据集可以防止患者身份信息的泄漏,因为它限制了个人与其记录的联系概率(概率为1/k)。通过调整参数k控制隐私级别。由于k匿名模型针对所有属性集进行处理,因此会出现某个属性匿名不足的情况,因此研究者基于k匿名模型提出了l多样化(l-diversity)模型、k-map模型和(k,1)-anonymity模型等身份信息隐私保护模型[6-7]。表2在表1基础上进行k-匿名处理。从表2数据可以看出,即使攻击者知道患者1在第一个分组中,也无法确定是哪一条记录,k-匿名能够解决身份泄漏的问题。
| 图表编号 | XD00140684900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.15 |
| 作者 | 侯梦薇、兰欣、邢磊、那天、陆亮 |
| 绘制单位 | 西安交通大学第一附属医院网络信息部、西安交通大学第一附属医院网络信息部、西安交通大学第一附属医院网络信息部、西安交通大学第一附属医院网络信息部、西安交通大学第一附属医院网络信息部 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}