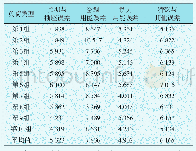
《表1 VGG与LSTM独立训练最终结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
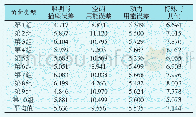
为了验证端到端增强特征的有效性,将本文算法与ELRCN进行比较,实验结果如表2所示。表2中,第1~2行为ELRCN在双层模型上得到的2条最优结果,第3行为端到端未加增强特征的结果,第4行为端到端增强特征模型的结果。由此可见,本文提出的端到端的模型效果明显,准确率介于ELRCN模型2次最优结果之间,但F1分数均高于ELRCN模型,端到端增强模型的F1分数高于ELRCN两个模型,分别为0.02和0.069。对比表1中非端到端的最终结果,端到端和端到端增强特征也有着明显的提升。最终预测结果的混淆矩阵如表3所示。
| 图表编号 | XD0084297800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.15 |
| 作者 | 陈乐、童莹、陈瑞、曹雪虹 |
| 绘制单位 | 南京邮电大学通信与信息工程学院、南京工程学院信息与通信工程学院、南京工程学院信息与通信工程学院、南京工程学院信息与通信工程学院 |
| 更多格式 | 高清、无水印(增值服务) |

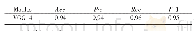


{kind=link}