《表3 不同学习率之下训练和识别的统计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
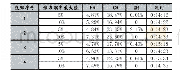
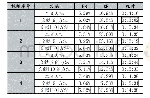
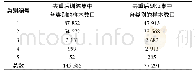
由于初始权值矩阵是随机生成的,同时学习率η也是根据经验选取的,需要考察使用不同的初始权值矩阵和学习率是否都能得到正确的识别结果。为此,设最大训练代数G=2 000,随机生成1 000组不同的初始权值矩阵,在不同的学习率之下分别进行感知器训练和测试样本识别,得到的结果见表3。从表3中结果可以知道,对于不同的学习率和初始权值矩阵,2 000代之内感知器训练均能收敛,并且得到的感知器均能正确判断测试水样的类型。这与感知器理论中的经典结论[15]:线性可分问题总能在有限次训练之后收敛到一个稳定的权值矩阵,该权值矩阵确定的感知器能够实现正确的分类,是吻合的;但是从计算效率的角度考虑,学习率η取值过大或者过小,都会增大训练代数,增加计算量,故对焦作矿区突水水源识别问题而言,建议学习率η在区间[0.050,0.200]内选取。
| 图表编号 | XD0082569000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.15 |
| 作者 | 彭程、刘永涛、尤文强、马红梅 |
| 绘制单位 | 华北科技学院电子信息工程学院、应急管理部煤炭安全监测监控技术安全生产重点实验室、华北科技学院电子信息工程学院、应急管理部煤炭安全监测监控技术安全生产重点实验室、华北科技学院电子信息工程学院、应急管理部煤炭安全监测监控技术安全生产重点实验室、华北科技学院电子信息工程学院、应急管理部煤炭安全监测监控技术安全生产重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}