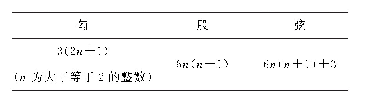
《表3 Host-to-Device多维数组复制》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于GPU并行枚举DES密钥Bitslice方法的实现》
数据组作为GPU不变参量传入,常量内存交换速度快,但速度也就相当于CPU的Cache缓存速率。因此设定传入GPU的常量数组或数据为share类型。但是通常share类型的数据存储容量非常有限,一般的share类型的容量仅有16K。实现线程ID与数据结构ID的关联时,则必须找到起始线程和寄存器之间复制关系代码,且由于CUDA使用的是地址复制,一般在一维数组的复制上很容易编程,而在二维、三维数组的复制时,必须找到代码与硬件调用之间的良好平衡。这也就是为什么CUDA的例子里很少有使用二维以上的数组。如表3所示为主机端到设备端的二维数组复制的方法。如果使用Stream流技术进行优化的话,需增加一维为流ID,则主机端(Host)到设备端(Device)的数据复制为三维数组复制。
| 图表编号 | XD007839200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 刘魁 |
| 绘制单位 | 石化盈科信息技术有限责任公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}